Transportation Management System
Transportation Management System RFP: How to Choose a TMS That Holds Up in Real Execution in 2026

Key Takeaways
- Most TMS RFPs shortlist vendors based on feature completeness, not execution resilience under volatility.
- Defining your operating model before writing requirements is the highest-leverage step in the process.
- An enterprise-grade RFP uses scenario-based demos and a weighted scorecard, not yes/no capability checklists.
- The difference between orchestration and routing determines which system survives real operational complexity.
- Locus processes 650M+ orders annually with 99.5% on-time delivery by connecting planning, dispatch, and execution in a single operational layer.
Hiring a dispatcher because they interview well is not the same as watching them run a shift when two drivers call out, or a carrier rejects a tender at noon. One shows you how they talk about the job. The other shows you how they handle the job when it gets messy.
Most enterprise Transportation Management System (TMS) RFPs still work like interviews. They reward vendors for checking boxes and showing polished workflows in perfect conditions. That is useful, but it is not the same as proving the system can hold up when plans break, cutoffs move, and exceptions stack up.
Vendors know how to answer feature questions. They have slides for every requirement line item. The gaps show up later, in production. Think mid-day replans, cascading exceptions, and last-minute capacity changes that force your team into manual firefighting.
This guide is built to help you avoid that. It walks through how to define your operating model, write scenarios that mirror real disruption, and score vendors on execution, not presentations. It also explains where Locus fits if you want to evaluate an execution-first platform.
The Real Job of a Transportation Management System RFP in 2026
A typical TMS RFP asks something like this, “Do you support multi-carrier tendering?” Vendors check the box, everyone lines up features in a spreadsheet, and the process turns into a price comparison.
A stronger, enterprise-grade RFP cuts into proof instead. For example: “Show me what happens when a carrier accepts a high-volume lane, then rejects it at 2 p.m., and we still have 47 orders that must move before the cutoff.”
You cannot answer that with slides. The vendor either runs it live or they cannot.
That difference matters because most cost overruns and service misses do not come from basic routing. They come from the messy handoffs between planning and execution. This is what breaks in real operations:
- A route that looked fine at 10 a.m. falls apart after a mid-day capacity hit
- Tendering slows down when acceptance rates dip and the system does not adapt
- The promise made at order creation no longer matches what the system does when cutoffs change
- The network needs node-aware decisions, but the tool only optimizes locally and leaves the hard calls to your team
If you choose a TMS based on features alone, you rarely see these cracks until go-live. A well-built transportation management system RFP pulls those edge cases into the open and forces vendors to prove how their system behaves when things go sideways.
For context on why older, module-heavy platforms struggle with these edge cases, this explainer on modern TMS architecture covers the structural differences.
Building a TMS RFP: Define Your Operating Model First
If you cannot clearly explain how your network behaves when it is under pressure, the RFP ends up full of generic statements. Vendors will fill in the gaps with assumptions that help them sell. Then selection gets driven by the best demo and the best price, and you risk buying a system tuned for someone else’s reality.
Do the operating model work first. Treat it as non-negotiable pre-work. Spend two to three weeks documenting how your operation actually runs, especially on your worst days.
That effort will save you months of fixes, workarounds, and painful reconfiguration after go-live. Here are a few more steps you can take:
Network and Volume Profile
Start by writing down what your network looks like on a normal Tuesday, then compare it to your toughest peak week of the year. You want the RFP to reflect both, because vendors tend to design for “average day” unless you force the real picture.
Map the basics in a way that is easy to validate internally:
- Node types and roles: DCs, hubs, micro-fulfillment, dark stores, cross-docks, partner nodes
- Who owns the SLA at each node: where the promise is made, and where it can get broken
- Modes and service tiers: parcel, LTL, FTL, same-day, white-glove, scheduled, and whether they mix at the same locations
- Lane patterns and constraints: time windows, hours of service, temperature control, restricted zones, and local delivery rules
When you get to volume, do not stop at average daily orders. The more important number is your peak-to-trough swing. A network that runs 8,000 orders on a slow Tuesday but 34,000 orders on the Friday before a major holiday needs a very different system than one that stays flat.
A practical way to capture it is to pull your three worst operating days from the last 12 months and document what broke. Where did planning fall apart? What caused dispatch to go manual? Which exceptions piled up? That pattern tells you what the TMS must handle better than any feature checklist.
Finally, be clear about your fleet mix. Private fleet, dedicated 3PLs, spot carriers, gig drivers, and asset-light partners all bring different integrations, workflows, and failure modes. A TMS that works well for a single-carrier setup often struggles when you are managing hundreds of transporters and constant variability.
SLA Exposure and the Cost of Being Wrong
Most enterprise RFPs mention SLAs, but they stop short of pricing the risk. If you do not spell out what a miss actually costs, vendors will treat it like a soft requirement. They will not feel the pressure your team lives with every day.
Start with your customer promise logic. What triggers a split shipment, a substitution, or a backorder? When a promise changes, what gets communicated proactively, and what only gets communicated after the fact?
Then, put real numbers behind the penalty zones:
- Chargebacks from retail partners
- Missed appointment fees at DCs
- Late-delivery credits and refunds
- Contract risk when service failures repeat
If you process 10,000 orders a day, a 5% increase in failed deliveries can translate to about $4.5M in annual losses. That should show up in the RFP, not only in your internal business case. It changes how vendors prioritize execution and exception handling.
Cutoff logic deserves its own section too. If a regional hub pulls its receiving cutoff forward by 90 minutes mid-afternoon, how many orders are impacted? What does the system need to do in the next 20 minutes to protect service?
That is not a checkbox requirement. It is a scenario. Put it in the RFP and make vendors show you how they handle it.
Integration Reality and Planner Workload Today
Your RFP should match the world you actually run, not the one a vendor assumes you have. Start by mapping every system that touches an order end to end. That usually includes ERP, WMS, OMS, finance, BI, carrier APIs, EDI gateways, and telematics. For each one, capture three things:
- How it integrates today (batch vs event-driven)
- How reliable the data is in practice
- Who owns master data when something breaks
If you are evaluating Locus, call out that it integrates natively with SAP (including S/4HANA), Oracle NetSuite, Microsoft Dynamics 365, Blue Yonder WMS, and SAP EWM. That gives you a baseline for scoping, instead of starting from a blank page.
Next, be direct about data quality. Missing dimensions, inconsistent weights, stale inventory, and messy timestamps are not edge cases. They are normal constraints a TMS has to live with. If a vendor never asks about data quality during the RFP, that is a red flag. Either they are not planning to integrate deeply, or they are setting you up for “it is your data” conversations later.
One more thing most RFPs miss is the best diagnostic input you already have: planner workload. Write down the top 10 reasons your planners override the system’s route, carrier choice, or allocation today. Every override points to one of two things: the system logic has a gap, or the system does not understand a real constraint.
Tip: Turn those overrides into scenarios in your RFP. If a TMS only automates the easy cases and still needs manual intervention when it matters, it has not reduced complexity. It has just moved the work around.
Suggested Read: 10 Best Retail Logistics Software Companies in India
The Execution Workflows Your RFP Must Test with Scenarios
Most TMS RFPs test capability: can the system do X? The question that matters is different: show me how the system handles X when Y also happens at the same time. Build your RFP around that framing.
Orchestration Versus Routing: Why the Distinction Matters
Routing answers a straightforward question: how does this order get from node A to the customer? Whereas orchestration answers the harder one: given where inventory sits right now, what carrier capacity is actually available, which SLAs are at risk, and what is happening across the network, which node should fulfill the order, which carrier should move it, and when should that decision change.
In an enterprise setup with multiple nodes and constant volatility, routing alone leaves the toughest calls to planners. Your RFP should test for orchestration with a real scenario: a node hits a capacity constraint and volume needs to shift to another node fast enough to protect cutoffs and service.
Get vendors to show you the automated decision, end to end, not a manual override. If they cannot, you are likely looking at routing plus visibility, not true orchestration.
Decision Automation Under Volatility
It is the stress test that separates a nice demo from a system that can handle real operations. Build four to six scenarios and have vendors walk through each one end to end on a shared screen in the live product, not a recorded walkthrough.
- Carrier rejection cascade: Primary carrier declines a high-volume lane at 2 p.m., with 47 orders needing assignment before the 4 p.m. cutoff.
- Mid-day cutoff change: A retail partner moves its DC cutoff up by 90 minutes with two hours’ notice, and 23 orders are already planned.
- Inventory reallocation: The WMS shifts a high-priority SKU to a different node at 11 a.m., impacting 15 open orders planned from the original node.
- Capacity collapse on a lane: A carrier disruption knocks out 30% of planned afternoon capacity.
- What to show for every scenario: Trigger for replanning, constraints honored, what happens automatically, what needs human approval and a logged reason.
Control Tower Visibility and Exception Management
Exceptions are normal in logistics. What matters is whether you spot them early, route them to the right person, and resolve them the same way every time. A dashboard can show you problems, but it does not guarantee the operation responds fast enough to protect service.
During evaluation, push vendors to show you their exception model in detail. Can the system separate a late pickup from a carrier rejection, a failed delivery, an address issue, or a capacity shortfall, and can it rank severity so your team knows what to touch first? Ask who gets notified at each priority level and what someone can do without leaving the tool.
Also, overrides should be logged with who did it, when, why, and what it changed downstream. Then, enquire about what happens automatically when a delivery fails. Does the system retender, notify the customer, adjust slots, or route the shipment back to a hub, or does it sit in a queue waiting for manual cleanup?
This is where Locus’s Control Tower Software is designed to be different. It predicts SLA risk 15 to 30 minutes before a miss based on live progress and traffic patterns, so teams can intervene early.
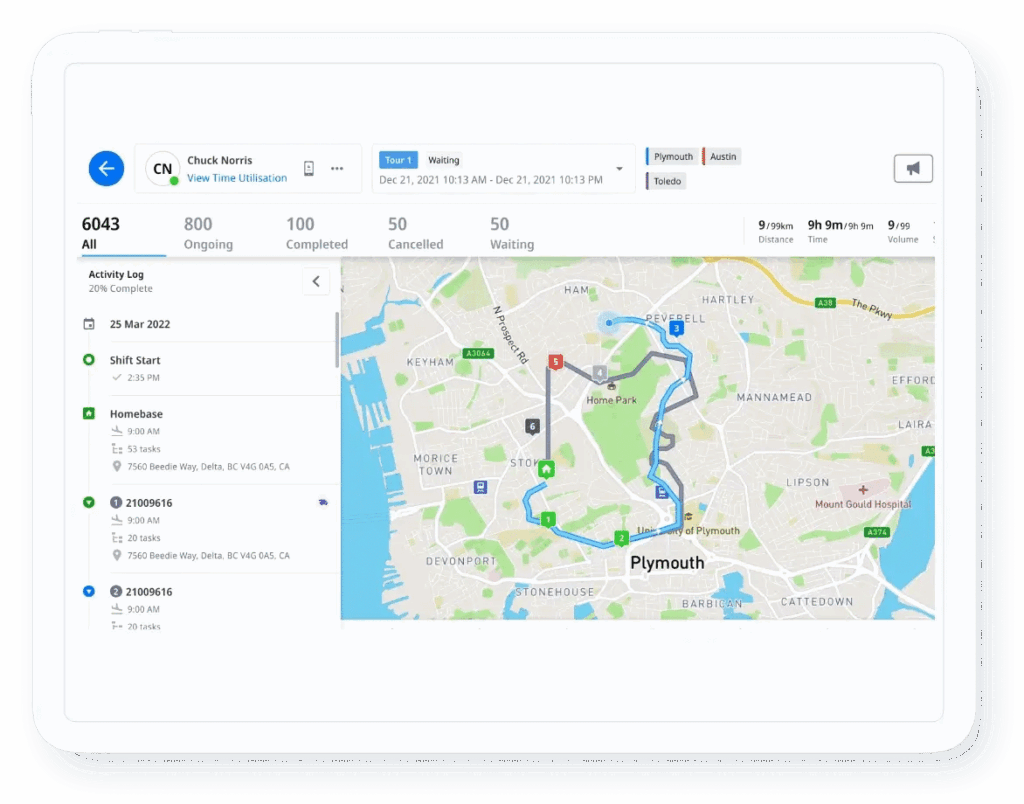
Instead of only telling you “the vehicle is here,” Locus can surface “this stop will be 8 minutes late,” and pair that with actions like proactive customer updates and a reroute. At scale, that shift from reacting to preventing is what keeps exceptions from turning into a full-day firefight.
Dispatch Workflows to Match How Work Gets Done
Dispatch is where planning becomes real execution. During evaluation, have vendors show dispatch in a live, working flow. Ask to see the dispatcher work queue, how SLA-at-risk orders get prioritized, and what it takes to reassign work when a driver cancels or a vehicle breaks down.
It’s always recommended to pay attention to how handoffs are captured between planners, dispatchers, and customer service, because that is where things get lost when pressure is high. If reassigning one order takes five screens, or if the system locks edits during optimization, teams will create workarounds.
Those workarounds turn into tribal knowledge, and the operation becomes fragile whenever your strongest dispatcher is not on shift.
For a clear baseline definition to align internal stakeholders before the demo, this overview of dispatch management covers the core workflow components.
TMS RFP: Enterprise Requirements That Separate Demo-Ware from Production-Ready
These categories do not show well in demos but determine whether you are still on the same implementation in year three.
Modular, API-First Integration Architecture
For an enterprise TMS in 2026, integration should be built around event-driven APIs, not file drops and batch syncs over EDI.
In the RFP, push vendors past “we can integrate” statements. Ask them to spell out API coverage for the core objects and events you actually run on, like order creation, route assignment, carrier acceptance, delivery confirmation, and exception flags. Then, dig into what happens when something changes mid-day. Can the system react in real time, and can you extend rules and workflows without turning every tweak into a paid services project?
Locus is built on a RESTful, API-first architecture compatible with ERP, WMS, OMS, and carrier ecosystems without requiring infrastructure replacement. Individual modules, including the geocoding engine and routing APIs, can be adopted independently. Moreover, integration can start narrow and expand progressively rather than requiring a full-platform cutover on day one.
Question any vendor on your shortlist for a reference architecture diagram and their minimum-viable integration plan for your specific stack. How they respond tells you a lot about implementation maturity.
Scalability Benchmarks and Performance Under Load
Enterprise scale is not just volume. It is volatility plus volume. A system that routes 5,000 orders cleanly may degrade significantly when 12,000 orders hit the optimization engine simultaneously during a peak event.
So do not accept vague claims like “built for scale.” Seek for specifics tied to your peak profile: throughput benchmarks at your highest volumes, expected latency for time-sensitive decisions, and how long re-optimization takes when you need to reshuffle 40 orders fast.
Also ask what happens during partial outages or when an upstream API is slow or down. You want to know if the system degrades gracefully or falls over.
Locus processes 650M+ orders a year across 400+ cities, which means the algorithms have been tested in real operational messiness, not just clean benchmark data. That includes traffic variability, imperfect addresses, mixed fleet constraints, and multi-region compliance rules.
Tips: If a vendor cannot share concrete throughput and latency numbers during the RFP, take that seriously. It usually means you will be the load test.
Governance, Control, and Auditability
Once a TMS owns dispatch decisions, carrier relationships, and SLA commitments, it needs governance structures that match enterprise risk standards.
Look for role-based access controls aligned to your org design (planner, dispatcher, supervisor, read-only analyst), segregation of duties for configuration changes and override approvals, audit logging sufficient for SLA dispute resolution and operational post-mortems, and override mechanisms that allow human judgment without bypassing accountability.
This is not only an IT concern. Operations leaders who have survived an SLA dispute with a major retail partner understand the value of a timestamped audit trail that shows exactly who changed what, when, and why.
Run the Vendor Process Without Getting Trapped by Polished Demos
It is easy to get pulled into the best-looking demo and miss the execution risk hiding underneath. A tighter vendor process keeps the focus on how the system will perform in your operation, not how it presents in a sales call.
- Start with an enterprise TMS RFI to shortlist: Use an RFI to eliminate vendors who do not belong on your list before you invest in the full RFP. The RFI should quickly surface four things: operating-model fit, integration readiness, proof they can handle your peak volume, and a realistic implementation timeline for an operation like yours.
If a vendor cannot answer those clearly, the RFP will not fix it. The point is to get down to three to four serious options so the transportation management system RFP becomes a validation step, not a fishing expedition. - Run scenario-based demos and score them with weight: Build your scorecard around workflows and execution, not feature checkboxes. A reasonable starting point is: execution scenario performance (30%), integration architecture strength (20%), operating-model fit (15%), scalability and reliability proof (15%), implementation plan quality (10%), and ROI model credibility (10%).
Adjust based on your risk profile, especially if integration is your biggest unknown. Then insist on live demos on a shared screen. Recorded walkthroughs do not show how the system behaves when you change the scenario midstream. - Do reference checks that focus on similarity, not satisfaction: General satisfaction questions do not tell you much. What you need is context: does the reference customer look like you in network complexity, volume volatility, and SLA exposure?
Ask what broke in the first 90 days, what changed after go-live that the plan did not anticipate, and where manual work still exists and why. Vendors with a real track record can connect you with customers who will answer those questions directly. - Treat implementation realism as part of the product: Implementation is part of the risk. A system that needs 18 months and multiple migration cycles has a very different profile than one that supports a phased go-live in 90 days. Ask vendors to explain their data migration approach, who owns data quality cleanup, how training and change management work for dispatchers and planners, what day-two support looks like, and when hypercare ends.
If you are evaluating Locus, its modular architecture supports phased adoption, so teams can start with dispatch planning or control tower and expand over time as ROI is proven.
Enterprise TMS RFP Template and Requirements Checklist
Use it as the structural backbone of your RFP document. Each dimension should produce a vendor response you can score and compare.
- Operating model: Enquire vendors to reflect your operating reality before they propose a solution. Cover network structure (nodes, modes, regions, fleet mix), volume profile with peak variability, SLA commitments with penalty exposure in dollars, your current system stack with integration ownership, and how planners and dispatchers work today, including the override patterns you documented.
- Execution scenarios: Require end-to-end walkthroughs for the situations that break plans in real life. Include carrier rejection with re-tendering and fallback logic, a mid-day cutoff change with orders already in the plan, a lane capacity drop that forces network-level rebalancing, inventory reassignment that triggers a node switch for open orders, and a failed-delivery exception.
- Integration architecture: Make vendors document what they can actually integrate through APIs and events, not just what they claim to support. Learn about the coverage of core objects, their EDI and carrier connectivity approach, data model expectations and mapping ownership, and extensibility for custom rules and constraints. Request a reference architecture diagram for your stack.
- Scalability and reliability: Get numbers, not promises. Seek for throughput benchmarks at your peak order volumes, latency expectations for critical decisions, behavior during partial outages or dependency failures, multi-region assumptions, and what monitoring and alerting looks like in production.
- Governance and security: Treat controls as part of execution. Enquire after role-based access, segregation of duties for configuration and approvals, audit logging scope and retention, override guardrails, and compliance posture for the regions you operate in.
- Implementation plan: Score the plan the same way you score the product. Focus on phasing and milestones, data migration approach and ownership, change management and training for planners and dispatchers, support model with 30/60/90-day success metrics, and governance setup for ongoing configuration ownership after go-live.
- ROI model: Ask for a defensible ROI tied to your cost drivers, including cost per delivery reduction, SLA breach reduction, manual planning effort reduction measured in planner hours per day, and service metric targets. Require explicit assumptions so you can challenge the ones that do not match your operating reality.
Where Locus fits in a TMS RFP
Most of the framework above describes what a production-ready TMS needs to prove in real execution. Locus is built around that bar, especially in areas where “feature complete” systems tend to break under volatility.
Orchestration, not just routing
Locus’s DispatchIQ engine evaluates 180+ variables at once, including vehicle capacity, driver hours of service, time windows, live traffic, carrier acceptance probability, and cross-node inventory state.
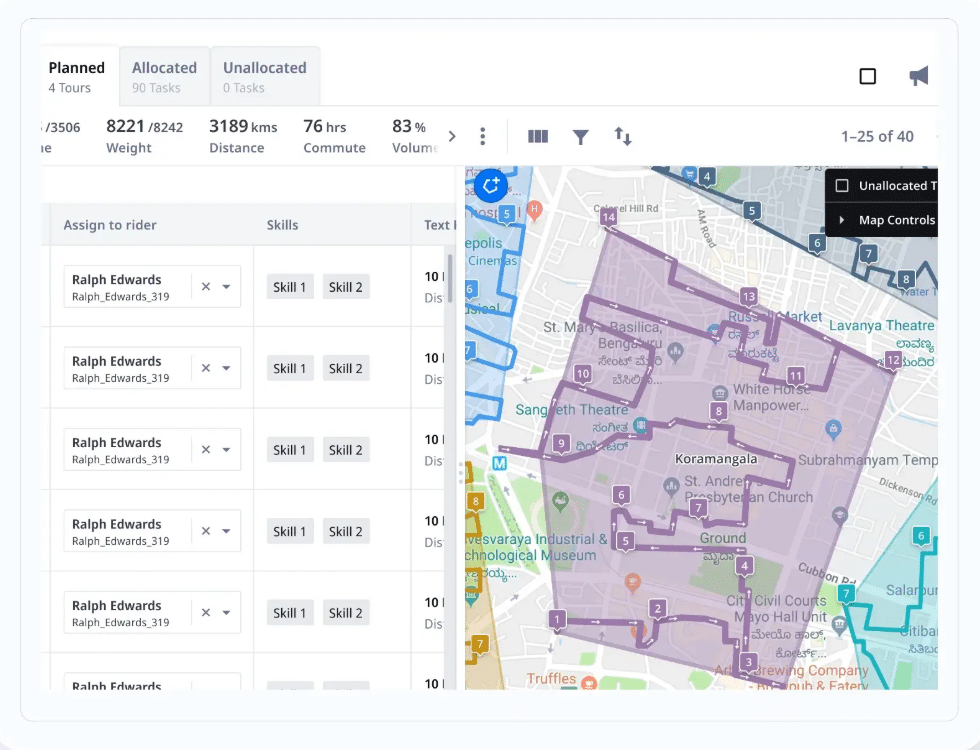
That lets it make routing and allocation decisions at the network level, not just optimize within a single node. When conditions change mid-execution, it re-optimizes automatically.
Customers using Locus have reported a 45% increase in deliveries per day with the same fleet and a 25% improvement in overall efficiency.
Decision automation that holds up under pressure
Dispatch teams make fast calls all day, and under pressure those decisions can be inconsistent. Locus automates the decisions that should be consistent, like carrier selection based on acceptance probability and cost, route sequencing based on time windows and SLA risk, and order clustering based on geography and constraint compatibility.
When a decision truly needs judgment, unusual exceptions, new network conditions, or customer escalations, it gets routed to the right person with the right context. That shift moves planners from constant firefighting to structured exception management.
Control Tower that intervenes
Most visibility tools tell you where a vehicle is. Locus’s Control Tower Software is designed to help you prevent misses, not just observe them. It predicts SLA breach risk 15 to 30 minutes ahead based on traffic and delivery progress, triggers proactive customer communication, and gives dispatchers recovery actions in the system instead of forcing a phone chain.
Across Locus customer operations, it has translated into a 38% reduction in WISMO contacts and 99.5% on-time delivery rates.
Architecture that fits into existing infrastructure
Locus is built on RESTful APIs with event-driven integration, so it can plug into your ERP, WMS, OMS, and carrier ecosystem without a rip-and-replace. Teams can adopt modules progressively, starting with dispatch planning or Control Tower, then expanding into hub operations and carrier orchestration as ROI is proven.
Capabilities like geocoding and routing APIs are also available as standalone services, which makes it easier to extend what you have rather than rebuild from scratch.
Across 650M+ orders in 30+ countries, Locus has been tested against the messiness that benchmarks rarely capture: regulatory variation, imperfect address data, mixed fleet constraints, and multi-carrier networks at scale. That production track record is what makes performance claims measurable in practice, not just theoretical.
Evaluate Locus against the scenario set in this guide, not against a demo checklist. Schedule a demo to learn more.
Frequently Asked Questions (FAQs)
1. Should we run an RFI before the RFP, or go straight to RFP?
Run the RFI first if you have more than five potential vendors or significant uncertainty about which platforms can handle your operating model. The RFI filters for fit; the RFP validates execution. Skipping the RFI compresses your timeline but increases the risk of spending full evaluation effort on vendors who should not have made the list.
2. How long should a TMS RFP process realistically take for an enterprise operation?
Six to twelve weeks is realistic: two to three weeks of operating-model documentation, two weeks for the vendor response period, two to three weeks for scenario demos and scoring, and one to two weeks for reference checks and commercial negotiation. Processes that move faster tend to skip the operating-model work, which produces the same gaps the RFP was meant to surface.
3. What is the most common reason TMS implementations fail after go-live?
The operating model documented in the RFP does not match how the system is actually configured. Generic requirements get interpreted by implementation teams who have never seen the operation under stress. The result is a system that holds up in normal conditions but requires manual intervention every time something unusual happens, which in enterprise logistics means daily.
4. How do we build a business case to justify TMS investment internally?
Anchor the business case in three cost pools: the current cost of SLA failures (chargebacks, missed appointments, lost contracts), the cost of manual planning labor and overtime during peak periods, and the cost of suboptimal carrier selection over a trailing 12-month period. A carrier rate variance analysis alone often justifies TMS investment before any efficiency gains are factored in.
5. What should we do if vendors refuse to demonstrate the scenario-based tests we specified?
Treat refusal as signal, not a negotiation point. A vendor who will not demonstrate their system under your specified scenarios during the sales process will not improve that behavior after contract signature. The scenarios represent your actual operational risk. A vendor whose system cannot handle them should not be on your shortlist.

General
How Enterprise Retailers Choose Fulfillment Solutions in 2026
Feb 23, 2026
A 2026 guide to retail fulfillment solutions like DC, 3PL, and hybrid. Learn where each model breaks and how orchestration keeps SLAs intact.
Read more
General
Routific Pricing Guide (2026): Packages, Reviews & Enterprise Alternatives
Feb 24, 2026
Routific Pricing: Key Takeaways How We Gathered Insights on Routific Pricing Routific publicly shares pricing information, but understanding real-world value requires analyzing user experiences alongside pricing data. To build this guide, we analyzed publicly available information from: These platforms provide insights from verified users across logistics, food delivery, retail, and service businesses. Rather than relying […]
Read moreInsights Worth Your Time












Transportation Management System RFP: How to Choose a TMS That Holds Up in Real Execution in 2026