General
What Enterprise-Grade Same-Day Delivery Infrastructure Actually Requires

Key Takeaways
- Same-day delivery has shifted from a competitive differentiator to a structural market expectation, with the global same-day fulfillment market reaching $14.4 billion in 2024.
- Enterprise same-day delivery requires five integrated infrastructure layers: distributed fulfillment topology, AI-powered dispatch, real-time inventory visibility, multi-carrier orchestration, and a dynamic delivery promise engine.
- Legacy logistics stacks fail at the same-day scale because static routing engines, siloed inventory systems, and manual dispatch processes were designed for batch-oriented operations with no requirement for continuous order ingestion.
- Locus’s constraint-aware dispatch engine and mid-route recalculation deliver a 45% increase in deliveries per day using the same fleet, with enterprises typically achieving 15-30% cost per delivery reduction in the first year.
Most enterprises attempting same-day delivery break down at the infrastructure layer. The promise gets made. The stack cannot execute it. Fragmented routing engines, manual dispatch processes, and zero cross-network inventory visibility were built for a world where next-day was the ambition and batch dispatch was the norm.
The logistics leaders feeling the pressure most acutely are running operational architectures assembled over years: a routing module from one vendor, a carrier management layer from another, a TMS predating the expectation of sub-four-hour windows across 1,000 concurrent orders.
None of it absorbs same-day velocity without human intervention at every decision point.
Enterprise-grade same-day delivery infrastructure requires five tightly integrated layers: distributed fulfillment nodes positioned within delivery range, AI-powered dispatch assigning orders in real time, live inventory visibility across every node, a multi-carrier orchestration layer managing owned and contracted fleets simultaneously, and a delivery promise engine committing only to windows the operation can honor.
In this guide, let’s take a closer look.
A Seven-Layer Model for Enterprise Same-Day Delivery Infrastructure
The five pillars define the core operating requirements. At enterprise scale, those pillars need to be translated into an execution model that connects demand capture, fulfilment readiness, dispatch, field execution, customer communication, data governance, and continuous optimisation.
A practical same-day delivery infrastructure model has seven layers:
- Capacity-aware order capture: the storefront or sales channel should only expose delivery options that can be fulfilled against inventory, picker availability, fulfilment node throughput, dispatch readiness, and last-mile capacity.
- Distributed fulfilment topology: stores, dark stores, micro-fulfilment centres, forward stocking locations, hyperlocal cross-docks, and partner nodes must sit close enough to demand density to make the service promise physically viable.
- Inventory and OMS integration: the order management system, warehouse systems, inventory feeds, and availability logic must operate from the same view of sellable stock and fulfilment constraints.
- AI-powered dispatch and route orchestration: routing, assignment, carrier selection, sequencing, and route recalculation need to happen continuously, not as a one-time start-of-day plan.
- Driver execution layer: the driver app, assisted navigation, proof of delivery, exception capture, and driver coaching turn optimised plans into on-ground compliance.
- Customer-facing visibility and recovery: predictive ETAs, proactive communication, dynamic slot management, and service recovery workflows protect the customer experience when execution conditions change.
- Operational data and governance layer: order, inventory, capacity, carrier, driver, route, customer, and exception data must feed a single operational data model with closed-loop learning.
This seven-layer model does not replace the five pillars. It expands them into the practical infrastructure sequence enterprises need when same-day delivery moves from a pilot service to a multi-market operating model.
Why Same-Day Delivery Has Become a Structural Expectation, Not a Differentiator
The same-day delivery market crossed $14.4 billion in global valuation in 2024. Amazon delivered 1.8 billion same-day and next-day packages in Q2 2023 alone, a 4x increase over the same quarter in 2019. Together, those figures describe a market floor. Enterprises competing in retail, FMCG, e-commerce, and 3PL now operate under an expectation of same-day delivery by default.
The gap between enterprises executing reliably and those announcing capability without backing infrastructure has widened fast. Understanding the source of the gap requires treating same-day delivery as a supply chain architecture problem.
Why the architecture layer is where same-day delivery breaks
Speed is rarely the binding constraint. Most enterprises have enough physical assets and carrier relationships to attempt same-day. Their logistics infrastructure was designed for a world where orders were batched, dispatched in the morning, and tracked loosely throughout the day.
Same-day delivery requires continuous order ingestion, sub-minute dispatch decisions, mid-route recalculation, and live SLA monitoring against a moving window. Batch-oriented infrastructure cannot absorb the cadence without human intervention at every decision point. Once volume scales beyond a few hundred orders per day, the manual intervention model collapses.
The operational stakes for enterprises
Retailers committing to same-day without rebuilding dispatch and visibility infrastructure have faced delivery failures during peak weeks, brand damage from missed windows, and customer service costs eroding the margin same-day was supposed to generate.
In 3PL operations, the failure mode appears as SLA penalties and contract renegotiations. In FMCG, it shows up as retailer chargebacks tied to missed replenishment windows.
The question for logistics leaders is not whether to build same-day capability. The question is which infrastructure investments, in what sequence, produce a reliable operation at enterprise scale.
5 Pillars of Enterprise Same-Day Delivery Infrastructure
Framing same-day delivery as a technology problem misses the architecture underneath it. Enterprises executing reliably at 5,000+ daily orders have five infrastructure layers working in coordination. A gap in any single layer limits the entire system.
For a deeper treatment of last-mile management techniques and how multi-carrier orchestration fits into the broader delivery model, Locus covers the operational fundamentals in precise terms.
1. Distributed fulfillment topology
Delivery speed at the customer end depends entirely on proximity at the fulfillment end. Same-day delivery in a metro area is physically achievable only when inventory is pre-positioned within the delivery radius. Micro-fulfillment centers, dark stores, and forward stocking locations all serve this function, but placement logic matters as much as node count. A retailer with 12 fulfillment nodes placed against actual order density and traffic patterns will outperform one with 20 nodes positioned for geographic coverage alone.
2. AI-powered dispatch and route orchestration
Dispatch at same-day velocity means assigning thousands of orders to drivers and vehicles within a window leaving no time for manual review. AI dispatch engines evaluate driver availability, vehicle capacity, delivery time windows, and live traffic simultaneously, producing assignment decisions in seconds.
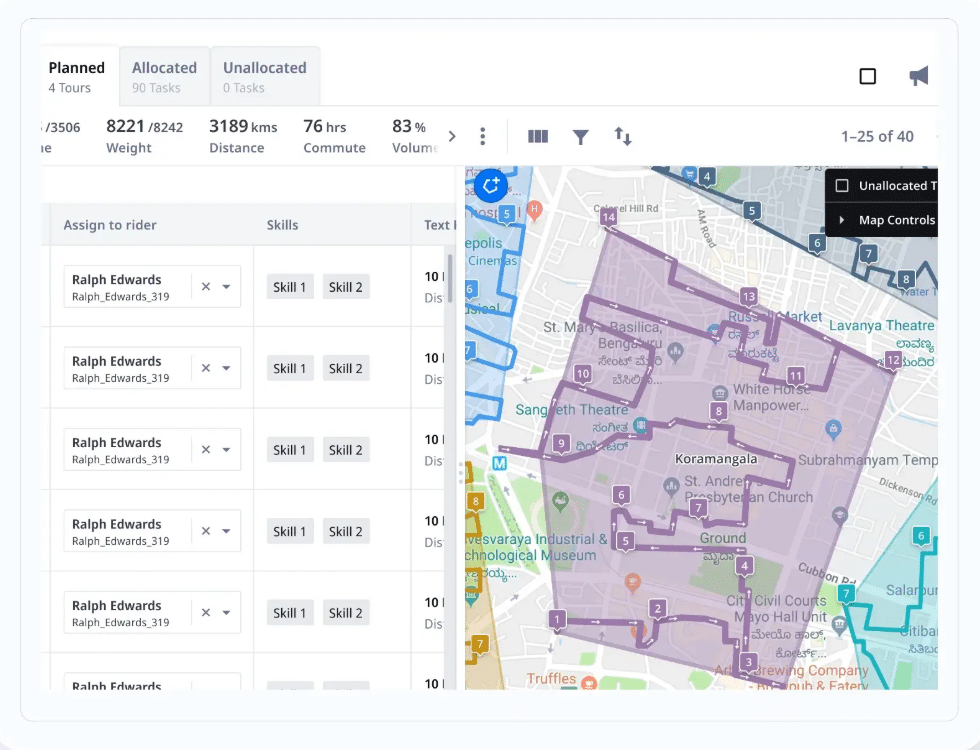
Locus’s dispatch management engine handles this through constraint-aware auto-assignment replacing manual dispatcher bottlenecks, maintaining consistent assignment quality regardless of how order volume fluctuates throughout the day.
Real-time inventory visibility across nodes
An order dispatched from the wrong node costs the same-day window. Without live inventory status across every fulfillment location, dispatch engines work with stale data and assign orders to nodes already depleted of the relevant SKU.
Real-time inventory visibility, synced across all nodes with sub-minute latency, is the precondition for any dispatch accuracy claim. Without it, the other four pillars operate on faulty inputs.
Multi-carrier and fleet orchestration
Enterprises do not run same-day delivery through a single carrier. Owned fleets handle dense urban zones, contracted 3PLs cover suburban and rural reach, and specialty carriers take high-value or temperature-controlled orders.
Managing all of it through separate portals produces no single view of capacity, no cross-fleet optimization, and no ability to rebalance dynamically when a carrier underperforms midday. A single orchestration layer tracking owned and contracted fleets as one pool is a structural requirement for any operation scaling across more than two geographies.
Dynamic delivery promise engines
A delivery promise the operation cannot honor is an infrastructure failure first, with customer experience absorbing the downstream cost. Promise engines connected to live capacity data, node proximity, and real-time carrier availability commit to delivery windows the operation can actually execute. Enterprises running promise engines disconnected from their dispatch and routing layers tend to over-promise during high-demand periods and absorb the service failure cost downstream in re-delivery expense and customer service volume.
Capacity-Aware Order Capture: Preventing Bad Promises Before Dispatch
Dynamic promise logic is only reliable when the order capture layer is connected to the operational systems that determine whether the promise is executable. Same-day delivery failures often begin before dispatch, when a storefront confirms a slot without validating fulfilment readiness and last-mile feasibility in the same decision flow.
A capacity-aware order capture model validates each same-day promise against five operational constraints before checkout confirmation:
- OMS integration: the order management system should connect demand capture to inventory availability, fulfilment node eligibility, delivery promise logic, and dispatch orchestration. If the OMS sees stock but the fulfilment node cannot pick, pack, and hand over within the required cut-off, the slot should not be offered.
- Inventory availability: sellable inventory must be checked at the node level, not merely at regional or network level. For mixed baskets, the system should account for whether all SKUs can be fulfilled from the same node or whether split fulfilment would invalidate the same-day window.
- Picker availability: picker capacity is a fulfilment readiness constraint. A store or dark store may have inventory on hand but insufficient labour to pick the order inside the required processing window. Same-day delivery infrastructure must treat picker availability as a gating input, not an afterthought.
- Fulfilment node capacity: each store, micro-fulfilment centre, or partner node has throughput limits by hour. The promise engine should understand order backlog, pick-pack capacity, staging space, dispatch cut-offs, and handover readiness.
- Last-mile capacity signals: fleet availability, carrier acceptance probability, route density, driver proximity, and active SLA risk should influence whether the customer sees a same-day slot.
This creates a closed commitment path: storefront demand flows into the OMS, the OMS validates inventory and fulfilment readiness, dispatch checks carrier and route feasibility, and the promise engine exposes only the slots that the operation can honour. For enterprises, this is the difference between using same-day delivery as a conversion lever and using it as a controlled, capacity-backed service promise.
| Infrastructure Pillar | What breaks without it | Failure mode at 1,000+ orders/day |
|---|---|---|
| Distributed fulfillment topology | Orders routed from distant nodes | Delivery windows missed in first-mile transit |
| AI-powered dispatch | Manual assignment bottlenecks | Dispatcher overload, incomplete dispatch cycles |
| Real-time inventory visibility | Assignment from empty nodes | Failed pickups, emergency re-dispatch at higher cost |
| Multi-carrier orchestration | Siloed fleet views | Capacity blind spots, no dynamic rebalancing |
| Dynamic promise engine | Commitments without capacity backing | Peak-week SLA failures, customer service surge |
The clearest dividing line in this table is the relationship between the promise engine and the dispatch layer. Enterprises investing in fulfillment node placement and carrier integrations while still running a disconnected promise engine will see service failure rates spike during the periods when customer expectations are highest.
Where Legacy Logistics Stacks Fail at Enterprise Scale
Legacy infrastructure does not fail visibly until volume crosses a threshold. A routing engine running static daily plans can handle 200 orders a day without obvious strain.
At 2,000 orders across multiple nodes, the same architecture produces dispatch delays, stockout blind spots, and a driver fleet executing routes optimized eight hours ago against conditions no longer reflecting reality.
The brittleness compounds with scale because legacy systems were built with assumptions baked in: order volumes follow predictable daily patterns, carriers perform consistently, and traffic data refreshes once per dispatch cycle. None of those assumptions holds at the same-day velocity.
Static routing and real-time constraints
A routing engine optimizing once at the start of the day locks in a plan against conditions at dispatch time. A traffic incident closing a major arterial at 1 pm, a driver running 25 minutes behind at stop four, or an order surge entering the system at 11 am: the static plan absorbs none of it. Drivers carry the deficit forward, stop to stop, while the routing system reports no deviation from plan.
Automated route planning solutions recalculating mid-route are architecturally different from static optimizers. The distinction is operational. Static tools optimize a plan once. Dynamic tools manage the delivery throughout their execution.
Siloed inventory across warehouses
An enterprise running seven fulfillment nodes with seven separate warehouse management system instances and no unified inventory layer is, from a dispatch perspective, operating seven independent businesses. Order assignment decisions made at the top of the dispatch cycle can be invalidated by stock movements at the node level the dispatch engine never receives.
In practice, this produces dispatch assignments to empty nodes, emergency re-dispatch at higher cost, and a driver productivity figure flattering the routing engine while the actual source of delay sits entirely in inventory management.
Manual dispatch at volume
Manual dispatch processes degrade in a specific way as volume rises: each individual decision requires more time while the window available per decision shrinks. A dispatcher managing 150 orders has roughly 20 seconds per assignment. At 600 orders, that window drops to 5 seconds. Assignment quality degrades, exceptions accumulate, and the dispatch cycle overruns the window that same-day delivery requires.
Enterprises adding order volume without rebuilding dispatch architecture carry this as operational debt, and it surfaces most visibly during peak seasons.
Multi-carrier coordination at scale
Enterprises covering Tier 1 and Tier 2 cities simultaneously might run owned fleets in metro areas, regional 3PLs for secondary cities, and hyperlocal carriers for dense urban same-day zones.
Coordinating across those carriers through separate systems, with separate performance dashboards and separate exception management, produces a logistics operation unable to rebalance dynamically and unable to confirm, at any given moment, whether the combined network will honor its SLA commitments for the day.
Generic logistics software cannot absorb the compounding complexity. Urban-rural geography combinations in Southeast Asia, India, and MEA add further variability: road infrastructure quality, regulatory delivery windows, and address standardization gaps all vary by city in ways a single-market routing configuration cannot account for.
How AI-Powered Dispatch and Dynamic Routing Change the Cost Equation
Dispatch and routing are the two most cost-intensive decision layers in same-day delivery. Together, they determine fuel consumption, driver utilization, delivery density per route, and whether the operation can absorb mid-day variability without human escalation. Getting both right is where the cost equation either holds or collapses.
Constraint-aware auto-assignment
Locus’s dispatch management engine evaluates each incoming order against a live constraint model: driver availability by zone, vehicle capacity and type, customer delivery windows, carrier rate structures, and real-time traffic conditions.
Assignment decisions run in seconds across thousands of concurrent orders, with no dispatcher reviewing individual assignments. From there, the dispatcher’s role shifts from making decisions to handling exceptions as the system escalates.
At 650 million orders processed across 400+ cities globally, the constraint model has been calibrated against a range of operational conditions a single enterprise fleet would take decades to accumulate. The calibration depth separates AI dispatch from rule-based systems: rule-based dispatch applies fixed logic consistently, while constraint-aware AI adjusts assignment weighting dynamically as conditions change throughout the delivery cycle.
Agentic Dispatch With Human-in-the-Loop Governance
The next maturity step in same-day delivery infrastructure is agentic dispatch: a governed operating model where specialised agents monitor conditions, recommend or execute decisions, and escalate only the exceptions requiring human judgement.
In an enterprise same-day network, four agent types matter most:
- Routing agents continuously evaluate stop sequencing, traffic, route density, driver progress, service time variance, and SLA risk. Their role is to identify when the current plan is no longer the best executable plan.
- Capacity agents monitor fleet availability, carrier acceptance, picker readiness, fulfilment node throughput, route saturation, and market-level demand. They inform whether new orders can be accepted, whether slots should be restricted, and where capacity needs rebalancing.
- Exception agents classify failed pickups, route deviations, late arrivals, failed handovers, address issues, vehicle breakdowns, and delivery window risks. Instead of presenting every exception to a dispatcher with equal urgency, they prioritise based on customer impact, SLA exposure, and recoverability.
- Communication agents trigger customer, driver, carrier, and operations updates based on the exception state. This extends the real-time communication layer by ensuring status updates are tied to live execution events, not static milestone rules.
Human-in-the-loop governance determines where automation stops. Low-risk actions, such as re-sequencing stops within the same route or sending a proactive delay notification, can be automated. High-impact decisions, such as reallocating premium carrier capacity, cancelling a same-day promise, overriding a delivery restriction, or changing service policy for a key account, should require dispatcher or manager approval.
This governance model preserves operational control while removing the manual decision load that makes same-day delivery brittle at scale.
Mid-route recalculation
Static routing considers its work done at dispatch time. Locus’s AI-powered route optimization keeps working throughout the delivery cycle, continuously recalculating paths as conditions change mid-route, re-sequencing stops when a driver falls behind, rerouting around traffic incidents, and inserting on-demand orders into live routes without triggering a new dispatch cycle.
The operational delta between these two approaches is measurable. Enterprises moving from static to dynamic routing typically see 30-40% reductions in delivery turnaround time, a figure translating directly into lower cost per delivery and higher fleet utilization across the same physical assets.
The Driver Execution Layer: Where Same-Day Plans Become Field Reality
The driver execution layer is the point where same-day delivery infrastructure either holds together or fails in the field. Even the best dispatch and routing plan depends on whether drivers receive clear instructions, can complete each stop correctly, and can capture exceptions in real time.
A dedicated driver execution layer should include:
- Driver app: the driver app is the operational interface for route start, stop sequencing, assisted navigation, proof of delivery, customer contact, barcode or OTP validation, failed delivery reason capture, and route completion.
- Assisted navigation: drivers need route guidance that reflects planned sequencing, delivery restrictions, parking constraints where available, and SLA priority. For dense same-day routes, generic navigation alone is not enough.
- Proof of delivery: photo capture, signature, OTP, geotagging, timestamping, and digital handover records reduce dispute risk and improve post-delivery auditability.
- Real-time exception capture: failed delivery reasons, customer unavailable events, address mismatches, damaged goods, payment issues, and access restrictions should flow into the control tower immediately rather than appearing in end-of-day reports.
- Driver assistance: coaching, next-best-action prompts, address support, customer contact guidance, and SLA-aware alerts help drivers make better decisions while routes are active.
For enterprises using owned, 3PL, and gig fleets simultaneously, the driver execution layer also standardises field behaviour across workforce types. Without that standardisation, route optimisation remains a planning exercise rather than an execution capability.
The FarEye and LogiNext constraint
Platforms such as FarEye and LogiNext offer route optimization within specific operational configurations, but their routing architecture is primarily start-of-day.
Once a route is dispatched, mid-route adaptation requires manual dispatcher intervention. At same-day volumes, the intervention gap is where delivery window breaches accumulate.
An operation with 600 active deliveries cannot absorb manual rerouting decisions for each traffic event. The optimization must run continuously throughout the delivery cycle.
Enterprises evaluating AI dispatch should ask a direct question in any vendor demonstration: show what happens to a live route when a driver falls 20 minutes behind at stop three. The answer separates dynamic orchestration from static optimization with a modern interface.
If your operation is running above 800 daily deliveries and still managing dispatch manually, see how Locus handles constraint-based assignment at scale.
Real-Time Visibility as the Connective Tissue of Same-Day Operations
Visibility in a same-day delivery operation is not a customer experience feature. For logistics leaders managing multi-node, multi-carrier networks, real-time visibility is the operational layer determining whether exceptions get caught in time to intervene or surface as completed failures at the end of the day.
A unified control tower view replaces five parallel monitoring workflows: carrier portal tabs, spreadsheet SLA trackers, dispatcher phone calls, customer service escalations, and post-day exception reports. The cost of those parallel workflows goes beyond operational time. It is the latency between an exception occurring and an intervention becoming possible.
What enterprise-grade visibility actually covers
Locus’s Control Tower gives logistics teams a live view of every delivery in motion across in-house and 3PL fleets, with exception detection and SLA monitoring in the same interface. Three specific capabilities define the difference between genuine visibility and dashboard theater.
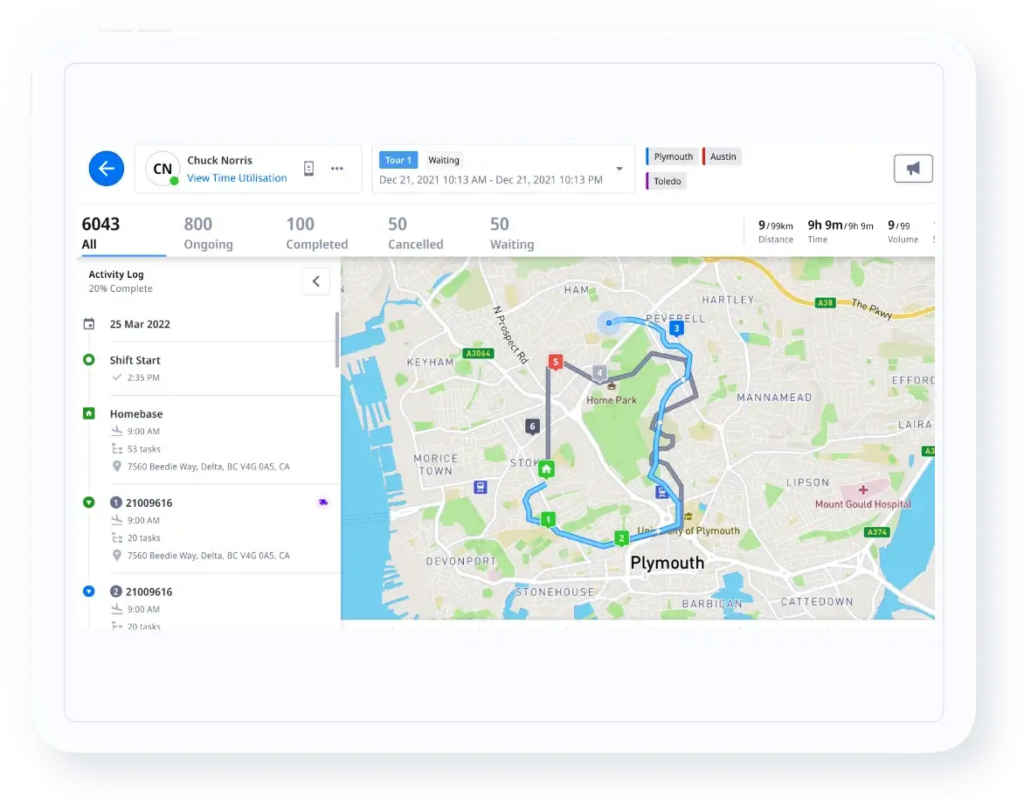
Predictive SLA breach detection flags routes heading toward a missed delivery window 15-30 minutes before the breach occurs, when intervention is still possible. After the breach, the alert has no operational value. Exception auto-escalation routes delivery failures, unauthorized route deviations, and failed pickups to the relevant team tier without requiring a dispatcher to monitor every driver simultaneously.
Carrier performance dashboards aggregate on-time rates, deviation frequency, and first-attempt delivery rates across all carriers in a single view, making carrier reallocation decisions data-driven rather than relationship-driven.
For enterprises managing high exception rates, the detailed treatment of managing delivery exceptions covers how operations structure exception workflows at scale. The role of real-time communication in delivery fulfillment is directly relevant to any operation where customer-facing notifications connect to live tracking data.
The fragmented tracking alternative
The alternative to a unified control tower is an operations team toggling between a 3PL’s portal, an owned fleet GPS system, a manual spreadsheet for SLA tracking, and email threads for exception escalation.
At 200 orders a day, the model functions. At 2,000 orders across eight carriers and five fulfillment nodes, the latency in each toggle adds up to missed intervention windows across multiple routes per shift.
Locus’s 38% reduction in WISMO (Where Is My Order) calls across its customer base reflects what happens when proactive status updates reach customers from a visibility layer accurately tracking each delivery in real time.
Customer-Facing Visibility and Automated Service Recovery
Customer-facing visibility becomes strategically important when it moves beyond “track my order” and starts reducing exception cost. For enterprise same-day delivery, customers need accurate, proactive, and recoverable delivery experiences.
Three capabilities define this layer:
- Predictive ETAs: customer-facing predictive ETAs should reflect live route progress, traffic conditions, service time variance, driver location, and remaining stop sequence. This is different from internal predictive SLA breach detection. The customer ETA must be understandable, stable enough to build trust, and responsive enough to reflect meaningful operational changes.
- Dynamic slot management: delivery slots should open, restrict, or shift based on live capacity and route feasibility. If a fulfilment node falls behind or a carrier reaches capacity, the system should narrow same-day options before orders are accepted. If route density improves or capacity becomes available, the system can expose additional slots.
- Service recovery automation: when a delivery is at risk, recovery workflows should trigger before the failure becomes final. This can include proactive customer notifications, same-day reattempt offers where feasible, alternate time-window selection, escalation rules for high-value orders, and structured exception resolution paths for operations teams.
The goal is not simply to inform the customer that a delay has happened. The goal is to preserve the promise where possible and recover the relationship when the original promise is no longer executable.
Building for Scale: From Regional Same-Day to Multi-Market Orchestration
Scaling same-day delivery from a single metro to a multi-city or multi-country network is an architectural problem most enterprises underestimate at the outset. Decisions seeming local at 500 orders per day in one city become structural constraints at 10,000 orders across five cities.
Fulfillment node placement and carrier mix strategy
Node placement decisions made for a single market need revisiting when the network expands. A dark store positioned for maximum coverage in Chennai may create routing inefficiencies in Pune because order density patterns differ by city. Carrier mix strategy changes by geography, with different 3PLs offering cost-quality tradeoffs varying by market. An orchestration layer recalculating carrier allocation per market, rather than applying a uniform national contract, produces meaningfully different cost-per-delivery outcomes at the city level.
The principles governing supply chain network design apply directly to the node placement and carrier mix decisions determining same-day delivery viability in each new market a business enters.
Partner vs. Self-Build for Local Fulfillment Networks
Enterprises scaling same-day delivery usually face a network design question before they face a software question: which fulfilment assets should be owned, which should be partnered, and which should be introduced only in high-density markets?
The main options are:
- Stores as fulfillment nodes: retailers with an existing store footprint can use stores as fulfilment nodes when inventory accuracy, picker capacity, staging space, and dispatch handover processes are mature enough. This model works best where stores sit close to demand density and can absorb digital order volume without damaging in-store operations.
- Dark stores: dedicated fulfilment locations reduce customer-facing store complexity and improve pick-pack productivity, but require real estate, labour planning, and inventory allocation discipline.
- Micro-fulfilment centres: automated or semi-automated micro-fulfilment can support high-density demand zones where throughput and inventory accuracy justify the capital and integration effort.
- Hyperlocal cross-docks: hyperlocal cross-docks support consolidation and rapid last-mile handoff without holding deep inventory. They are useful where inbound replenishment can be synchronised with same-day dispatch waves.
- Third-party fulfilment partners: partners can accelerate market entry, especially in new geographies, but introduce dependency on external quality standards, inventory discipline, exception management, and integration maturity.
The right model is rarely binary. Mature enterprise networks often combine owned nodes in dense markets, partner fulfilment in expansion markets, and cross-dock capacity where demand justifies faster local consolidation.
How to Vet Same-Day Fulfillment and Delivery Partners
Partner-led same-day delivery only works when partner capability is assessed at the same operational depth as owned infrastructure. Enterprises should evaluate partners against the following criteria:
- Node coverage: proximity to target demand clusters, cut-off times, storage capability, and geographic reach by service zone.
- SLA history: documented performance by market, delivery window, carrier type, and seasonality rather than blended network averages.
- Quality standards: pick accuracy, packing compliance, temperature-control capability where relevant, damage rates, and proof-of-delivery discipline.
- Exception handling maturity: ability to classify, escalate, and resolve failed pickups, missed handovers, address issues, customer unavailability, and inventory mismatches.
- Carrier integrations: readiness to connect with enterprise dispatch, carrier management, tracking, and customer communication systems.
- Cost structure: transparent pricing for storage, picking, packing, staging, handover, delivery, reattempts, returns, and peak surcharges.
- Market-level performance data: city-level and zone-level evidence of reliability, not just national or regional headline performance.
The strongest partners do not merely provide capacity. They provide operational consistency, reliable data flows, and exception discipline that can be orchestrated alongside owned fulfilment and fleet assets.
Localized SLAs and regulatory variations
Same-day delivery in Southeast Asia, MEA, and India operates under fundamentally different last-mile conditions than North America or Western Europe. Address standardization is lower across APAC markets, requiring geocoding engines trained on informal and partial address patterns. Regulatory delivery windows vary by city and cargo type. Fleet composition differs at the structural level: two-wheelers dominate urban last-mile delivery in India and Southeast Asia without equivalent in North American or European networks.
Locus’s proprietary geocoding engine, patent-protected and trained on address patterns across 400+ cities including emerging market geographies, handles the address resolution problem generic routing engines fail on in these conditions. The routing logic accounts for regulatory delivery windows, cargo restrictions, and fleet type eligibility at the market level, rather than requiring separate configuration instances per geography.
One orchestration layer versus regional point solutions
Enterprises solving each new market by adopting the dominant local logistics tool end up with a stack of regional point solutions: different visibility interfaces, different exception management workflows and different carrier integration architectures.
Adding a new market means new system onboarding, new training cycles, and new reconciliation efforts between systems sharing no data or common operational context.
A single orchestration layer adapting to local constraints, carrying configuration logic per geography, and running a unified control tower across all markets is structurally superior to the fragmented stack for any enterprise operating across more than two regional markets simultaneously.
The Single Operational Data Model Behind Same-Day Execution
Same-day delivery infrastructure depends on a single operational data model connecting systems that have historically operated separately: OMS, WMS, inventory systems, dispatch, carrier management, driver apps, customer communication, and analytics.
The single operational data model should bring together:
- Order data: basket composition, promised slot, customer priority, service policy, delivery restrictions, and cancellation rules.
- Inventory data: node-level stock, substitution logic, sellable availability, reservation status, and replenishment constraints.
- Capacity data: picker availability, node throughput, carrier capacity, fleet availability, driver shifts, and route saturation.
- Route data: sequencing, service time, travel time, geocodes, traffic context, stop priority, and SLA risk.
- Carrier and driver data: acceptance rates, performance history, cost structures, eligibility, driver location, route adherence, and proof-of-delivery status.
- Customer data: communication preferences, delivery instructions, contactability, previous failed delivery patterns, and consent rules.
- Exception data: cause codes, escalation paths, recovery actions, resolution time, and financial impact.
The objective is a closed-loop decision flow: the system senses demand, inventory, capacity, and field conditions; decides the best fulfilment, dispatch, routing, and recovery action; executes through carrier and driver workflows; then learns from outcomes to improve future promises, route plans, capacity rules, and exception handling.
Without this closed-loop sense-decide-execute-learn cycle, enterprises optimise isolated steps while the system as a whole remains reactive. With it, same-day delivery infrastructure becomes progressively more accurate as execution data feeds back into planning and orchestration.
Build vs. Buy: How Enterprises Should Evaluate Same-Day Delivery Infrastructure
The build vs. buy decision for enterprise same-day delivery infrastructure should be made layer by layer. Some capabilities may justify internal ownership. Others require specialised optimisation depth, carrier connectivity, or multi-market execution logic that is difficult to build and maintain internally.
A practical evaluation should separate the following areas:
- Orchestration layer: building internally may offer control, but buying or partnering can reduce time to value where routing, dispatch, carrier management, visibility, and analytics must work together from day one.
- Routing and optimisation: internal teams can build simple routing logic, but dynamic same-day routing requires constraint handling, mid-route recalculation, traffic awareness, geocoding depth, and operational calibration across varied markets.
- Visibility and control tower: enterprises should assess whether internal dashboards can support live exception detection, SLA monitoring, carrier performance analysis, and customer-facing updates at operational latency.
- Geocoding and address intelligence: self-build is difficult in markets with inconsistent address formats, informal landmarks, and variable road networks.
- Carrier management: buying or partnering can accelerate access to pre-integrated carriers, performance data, service rules, and allocation logic.
- Analytics and governance: internal analytics teams can own business reporting, but operational analytics must be tied directly to plan-versus-actual execution data.
The build vs. buy decision should be tested against six criteria:
- Time to value: how quickly can the capability support live same-day operations?
- Integration effort: how much work is required to connect OMS, WMS, dispatch, carrier, driver, and customer systems?
- Data maturity: does the organisation have the data quality and operational history required to train and maintain decision logic?
- Governance requirements: which decisions need auditability, approval controls, and exception oversight?
- Scalability: can the capability support multi-node, multi-carrier, multi-market operations without rebuilding the architecture?
- Total cost of ownership: what is the long-term cost of engineering, maintenance, support, optimisation, integrations, and change management?
For many enterprises, the most resilient model is not pure build or pure buy. It is a platform-led orchestration layer integrated with internal systems, governed by enterprise process owners, and extended through partner capabilities where market entry speed or specialist infrastructure matters.
Measuring What Matters: Infrastructure ROI Metrics for Enterprise Logistics Leaders
The infrastructure investments required for enterprise same-day delivery are substantial. Distributed fulfillment nodes, AI dispatch systems, real-time visibility infrastructure, and carrier integration architecture all carry significant setup and operational cost. The investment case must be built in the metrics VP and CXO-level decision-makers can track directly.
Core KPIs and the compounding effect of volume
- Cost per delivery is the primary financial metric. Enterprises implementing AI-driven route optimization with dynamic dispatch typically achieve 15-30% cost per delivery reduction in the first year, driven by higher route density, lower fuel consumption, and reduced re-delivery rates.
For a company processing 10,000 daily orders, a 5% increase in failed delivery rate alone produces an annual loss of approximately $4.5 million, based on operational modeling across Locus’s customer base. - On-time delivery rate measures service reliability. Locus customers across retail, FMCG, and 3PL verticals reach 99.5% on-time delivery rates across multi-region networks. At the volumes where same-day is a competitive necessity, on-time rate is also a contract metric tied directly to retailer chargebacks and 3PL SLA penalties.
- Fleet utilization measures the efficiency of physical assets. A 45% increase in deliveries per day using the same vehicle fleet, achieved through better route density and dynamic assignment, represents a capital efficiency gain deferring fleet expansion investment. For logistics leaders building an investment case, it is a direct ROI line against capital expenditure.
- Delivery exception rate measures operational reliability at the tail. Enterprises running 1,000+ daily deliveries see disproportionate gains from AI-driven orchestration because optimization compounds with volume: a routing engine improving route density by 12% produces 120 additional completed deliveries per 1,000 dispatched, and the gain scales linearly with volume.
| KPI | Typical baseline (manual/static routing) | With Locus AI orchestration |
|---|---|---|
| Cost per delivery | Baseline | 15-30% reduction in year one |
| On-time delivery rate | 85-92% | Up to 99.5% |
| Deliveries per day, same fleet | Baseline | 45% increase |
| SLA compliance | Baseline | 8% improvement |
| WISMO customer contacts | Baseline | 38% reduction |
Operational gains from AI-driven dispatch and routing do not scale linearly with order volume. They compound. An operation at 5,000 daily deliveries sees proportionally larger gains than one at 500, because the optimization engine draws from a larger pool of order combinations when building high-density routes. Enterprises transitioning to AI-driven orchestration typically achieve positive ROI within 6-18 months of implementation.
Locus’s Analytics Studio surfaces these KPIs in a plan-versus-actual format, letting logistics leaders track infrastructure ROI against baseline without manual data aggregation across systems.
A Phased Roadmap for Scaling Same-Day Delivery Infrastructure
Enterprises should scale same-day delivery infrastructure in phases, not through a single high-risk transformation programme.
Phase 1: Assess
Map the current operating model across order capture, OMS, inventory, fulfilment nodes, dispatch, carrier management, driver execution, visibility, customer communication, and analytics. Identify where same-day promises are made without capacity validation and where exceptions are discovered too late to recover.
Phase 2: Pilot
Select one market, one fulfilment model, and a controlled delivery promise. The pilot should test capacity-aware order capture, dispatch automation, route optimisation, driver app adoption, customer ETA communication, and exception workflows against measurable baselines.
Phase 3: Integrate
Connect the OMS, WMS or inventory systems, dispatch engine, carrier layer, driver execution tools, customer communication systems, and analytics environment. Integration quality determines whether same-day delivery can move from a pilot into repeatable execution.
Phase 4: Scale
Expand by market and node type while preserving one orchestration model. Add carrier capacity, partner fulfilment, stores as fulfilment nodes, hyperlocal cross-docks, or micro-fulfilment only when local demand density and operating data support the investment.
Phase 5: Optimise
Use plan-versus-actual data to improve route density, slot availability, promise accuracy, picker staffing, carrier allocation, driver performance, and service recovery rules. Optimisation should be continuous because same-day delivery conditions change by hour, market, season, and customer segment.
This phased model reduces operational risk. It also gives logistics leaders the evidence needed to justify wider investment before same-day delivery becomes a margin-eroding promise.
Build a Same-Day Delivery Operation That Executes at Scale
The gap between announcing same-day delivery and executing it reliably at 1,000+ daily orders is an infrastructure gap. Closing it requires five tightly integrated layers, AI-powered dispatch working without manual intervention, and a visibility model catching exceptions before they become failures. Enterprises treating same-day delivery as a speed problem will rebuild it. Enterprises treating it as an architecture problem will scale it.
Locus delivers the orchestration layer connecting all five infrastructure pillars, with dispatch, routing, visibility, and carrier management running in a single operational context. Schedule a demo to see how it performs at your operation’s volume.
Frequently Asked Questions (FAQs)
1. What is the minimum fulfillment node density required to reliably offer same-day delivery in a metro area?
No universal threshold applies across all metro areas, but operational planning for same-day delivery typically requires fulfillment nodes within 10-15 km of 80% of target delivery addresses. Node density requirements increase in metros with high traffic variability, where travel time between zones is less predictable. Placement should be driven by order density maps and traffic pattern data over geographic coverage targets.
2. How does AI-powered dispatch differ from rule-based dispatch for enterprise-scale same-day delivery?
Rule-based dispatch applies fixed assignment logic consistently, regardless of conditions. Locus’s constraint-aware engine evaluates 180+ variables simultaneously, including live traffic, driver position, vehicle capacity, time windows, and carrier rates, and adjusts assignment weighting dynamically as conditions change. At 1,000+ daily orders, the assignment quality gap between the two approaches becomes measurable in cost per delivery and on-time rate within the first full operational month.
3. What are the biggest cost drivers in same-day delivery infrastructure, and how can enterprises reduce them?
Re-delivery costs and empty miles are the two largest controllable cost drivers. Re-delivery costs stem from low first-attempt delivery rates, which AI dispatch reduces by improving address accuracy and time-window compliance. Empty miles are reduced through higher route density, achieved through dynamic order clustering and mid-route assignment optimization. Enterprises implementing both measures through Locus typically achieve 15-30% cost per delivery reduction in the first year.
4. How should enterprises handle same-day delivery in mixed urban-rural geographies without inflating per-delivery costs?
The carrier mix strategy must be localized by geography type. Urban zones support owned fleet operations at high delivery density. Rural and suburban zones require contracted 3PL carriers whose per-delivery cost structure absorbs the lower stop density. A multi-carrier orchestration layer routing order allocation based on geographic type, carrier rate, and service-level history produces better cost outcomes than a uniform-fleet or single-carrier model. Locus’s ShipFlex module handles carrier allocation across 1,000+ pre-integrated carriers and 3PL partners.
5. What KPIs should logistics leaders track to measure same-day delivery infrastructure performance?
Cost per delivery, on-time delivery rate, first-attempt delivery rate, fleet utilization, and delivery exception rate are the five metrics directly reflecting infrastructure quality. Aggregate on-time rate masks geographic variation and node-level performance differences, so segmenting by fulfillment node and carrier is necessary for operational diagnosis rather than reporting. Locus’s Analytics Studio runs plan-versus-actual tracking across all five metrics at the route, driver, and node level.
6. How should enterprises decide whether to build or buy same-day delivery infrastructure?
Enterprises should evaluate the build vs. buy decision by capability. Internal teams may own business rules, customer policies, analytics interpretation, and fulfilment strategy, while platform partners can accelerate orchestration, dynamic routing, geocoding, carrier management, visibility, and exception workflows. The decision should consider time to value, integration effort, data maturity, governance needs, scalability, and total cost of ownership.
7. What systems need to connect for capacity-aware same-day order capture?
Capacity-aware same-day order capture requires the storefront, OMS, inventory system, WMS or fulfilment system, dispatch engine, carrier management layer, driver execution tools, and customer communication system to share operational signals. The promise shown at checkout should reflect inventory availability, picker availability, fulfilment node capacity, dispatch readiness, and last-mile capacity before the order is confirmed.
8. Why is a driver app part of enterprise same-day delivery infrastructure?
A driver app is part of the infrastructure because same-day execution depends on what happens in the field. The app gives drivers stop sequencing, navigation, customer contact, proof of delivery, real-time exception capture, and SLA-aware prompts. Without a standard driver execution layer, optimised dispatch plans can break down through missed handovers, incomplete proof, delayed exception reporting, and inconsistent field behaviour.

General
From Control Towers to Autonomous Supply Chains: The Shift from Visibility to Real-Time Execution
Apr 16, 2026
Explore how supply chains are evolving from control towers to autonomous execution systems. Learn why visibility is no longer enough and what leaders should invest in next.
Read more
General
AI Capacity Planning: How Predictive Intelligence Is Reshaping Peak Season Logistics
Apr 17, 2026
Learn how ML-powered demand forecasting and dynamic carrier orchestration help logistics operators cut peak season costs, protect SLAs, and optimize fleet utilization through constraint-governed optimization.
Read moreInsights Worth Your Time












What Enterprise-Grade Same-Day Delivery Infrastructure Actually Requires